1.概述
-
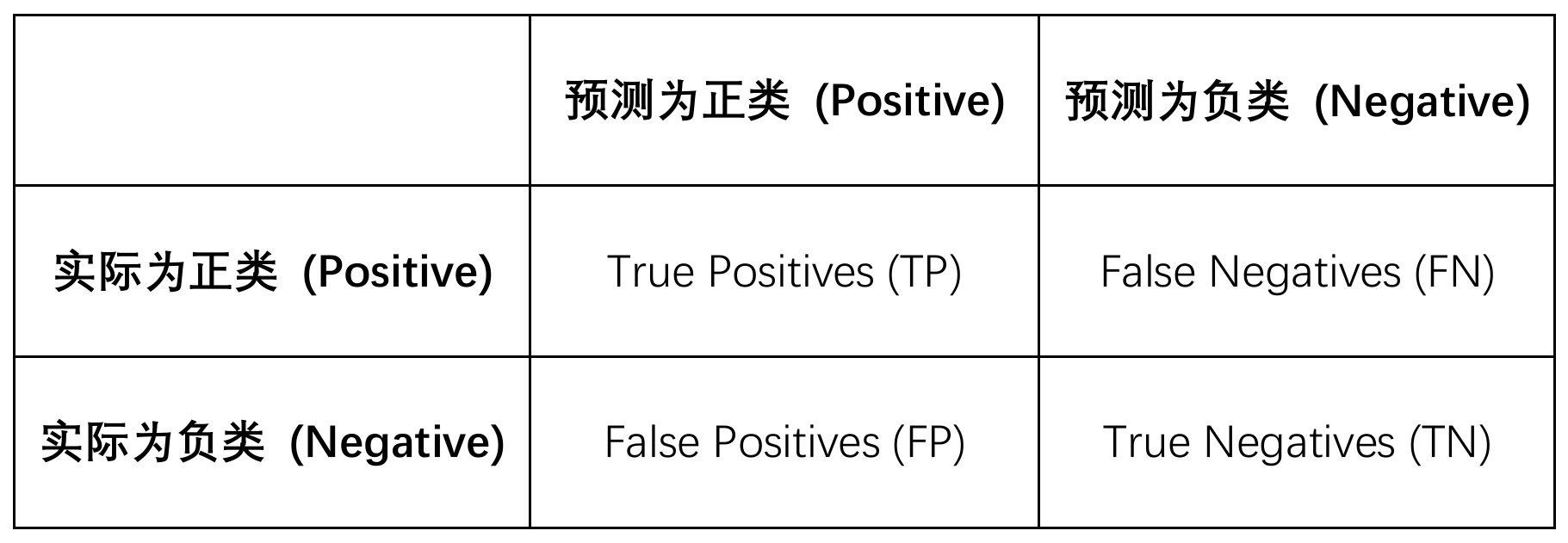
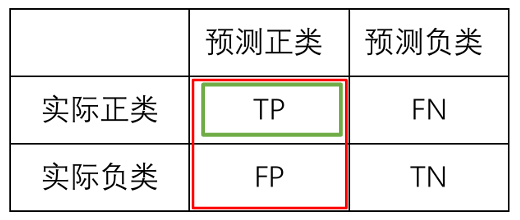
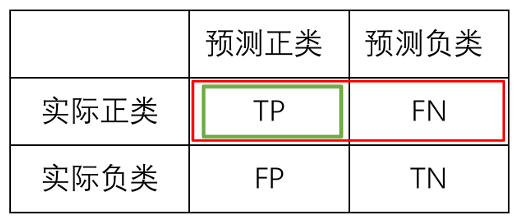
TP:真正,实际为正类且预测为正类的样本数,预测正确。
-
TN:真负,实际为负类且预测为负类的样本数,预测正确。
-
FP:假正,实际为负类但预测为正类的样本数,预测错误,误检。
-
FN:假负,实际为正类但预测为负类的样本数,预测错误,漏检。
2.精确率(Precision)
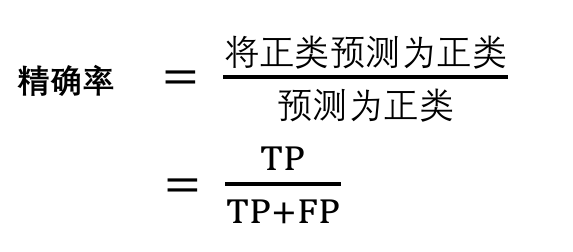
精确率 :又叫 查准率 ,将正类预测为正类 占 预测为正类的总数 的比例.
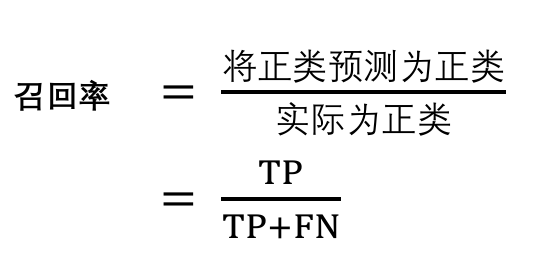
3.召回率(Recall)
召回率:又叫 查全率 ,将正类预测为正类 占 实际为正的总数 的比例.
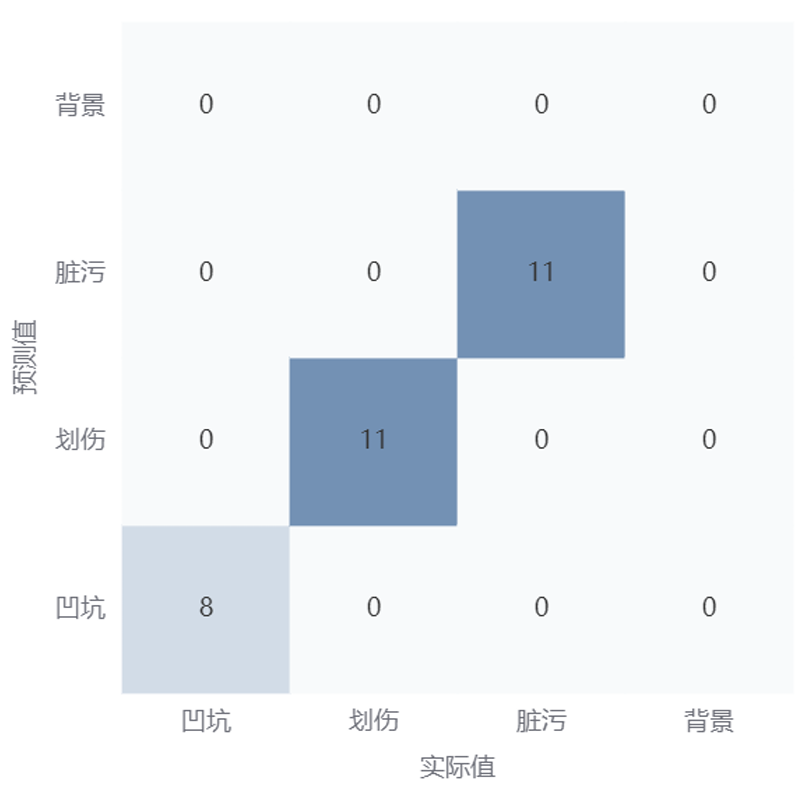
4.混淆矩阵
混淆矩阵提供了N x N 的表格,用来展示一个N元分类器的预测结果。混淆矩阵展现出模型对各个类别的学习情况,如存在模型在A类别学习效果较好,但在B类别上学习效果一般,拉低模型的整体指标。这种情况能通过混淆矩阵去分析判断。
下图所示的4X4的混淆矩阵,每一行表示一个预测值,每一列表示一个真实值。
例如第一列,共有8个实际凹坑,模型将8个凹坑全部预测为凹坑,模型对凹坑的预测全部正确。因此混淆矩阵可以帮助用户理解模型在不同类别上面的表现,从而帮助用户分析并优化模型。