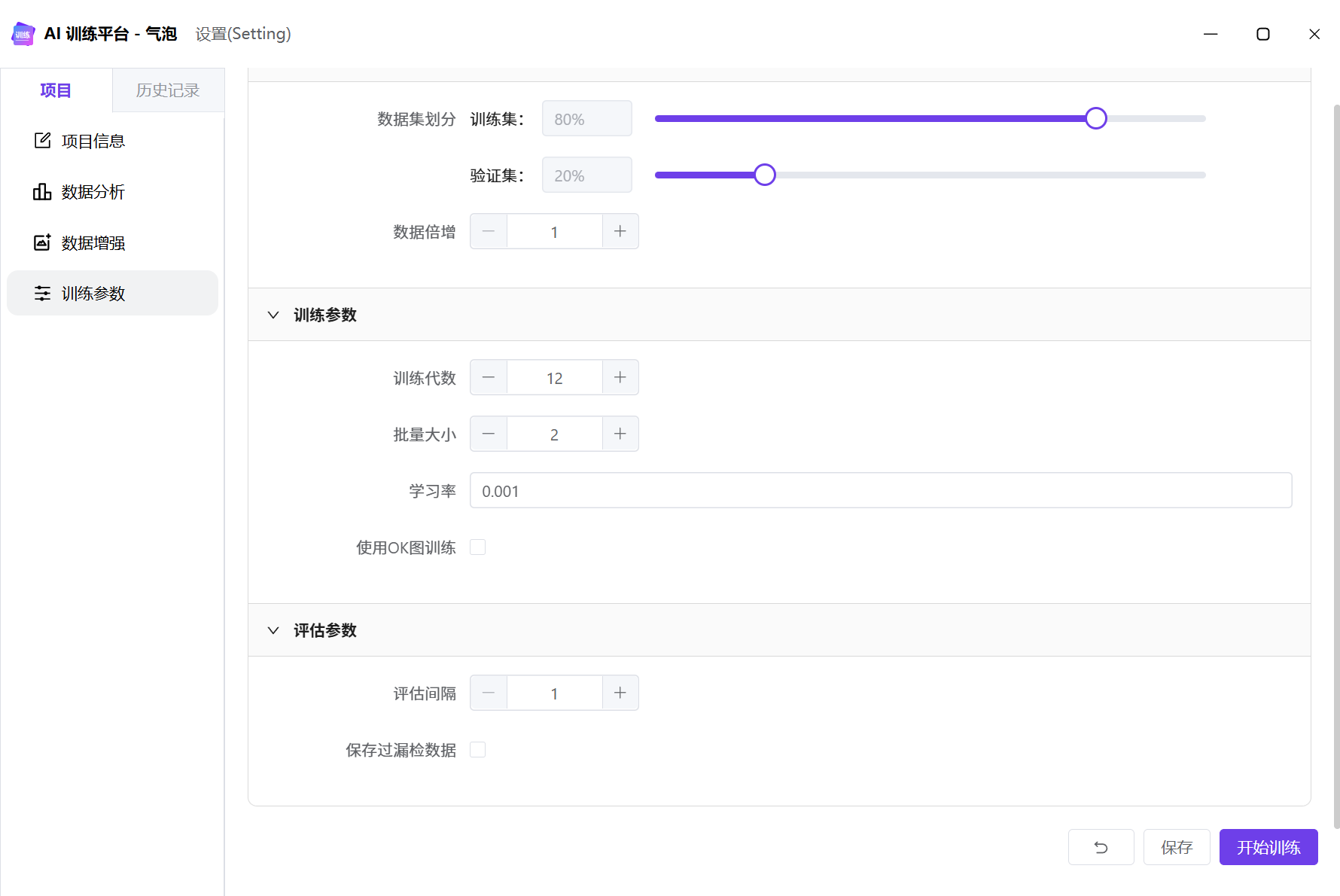
训练参数
训练参数分为以下几个部分:
- 数据参数
- 数据集划分
- 数据倍增
- 训练参数
- 训练代数
- 批量大小
- 学习率
- 使用OK图训练
- 评估参数
- 评估间隔
- 保存过漏检数据
下图是默认的训练参数:
数据参数
数据集划分

数据集划分是机器学习里非常重要的概念。我们通常会把数据集划分出一部分来,不参与训练,在训练时,使用这些数据去测试模型效果。这部分数据就是验证集。
少量数据的情况
在数据不多的情况下,比如少于1000张图,一般是分出来20%的数据,作为验证集。如果验证集数量太少,比如不到10张,测量的准确率就会有比较大的误差(不是100%就是90%,跨度太大)。
大量数据的情况
在数据量很大的情况下,比如大于10000张,我们就会适当减少验证集的比例,比如降到10%,或者更低。

这是因为训练数据非常宝贵,如果我们有10万张图,验证集还划分20%,就会白白浪费掉2万张图。收集这些图片是非常耗费精力的,我们应该充分利用这些数据。
如果有10个类,划分5%的数据做验证,每个类就有500张,就足以计算出比较准的指标(0.2%的区分度),是比较合适的。
数据极少的情况
如果训练数据实在是太少,只有10张,但是也想训练模型看看效果,可以直接将训练集设置为100%,验证集设置为20%,这时候验证集会使用训练集的最后2张图。因为模型已经见过这些图,所以评估指标通常是100%。

%%{init: {'theme': 'default', 'flowchart': {'curve': 'linear'}, 'gantt': {'width': 100}}}%%
gantt
title 数据集划分
dateFormat X
axisFormat %s
section 数据集
数据集: 0, 100
section 训练集
训练集: 0, 100
section 验证集
验证集: 80, 100
将训练集划分到100%,验证集也划分到100%,此时验证集就是训练集。这样也能训练出来模型,只不过因为所有的数据模型都见过,指标通常都是100%。

数据倍增
首先我们需要给出训练步数的公式:
总训练步数(step)=训练代数(epoch)*总数据量(len_dataset)/批量大小(batch_size)
一般来说,总训练步数必须达到一定数量,模型才能收敛,所以当数据量很少的时候(比如不到500张),都会使用数据倍增来增加训练步数。
有人可能觉得,增加训练代数也可以增加训练步数。这里有两个问题:学习率更新策略,以及空间占用问题。
在训练过程中,学习率的更新策略是按照12代设置的,第9代学习率降低10倍,11代再一次降低10倍。因此如果直接增加代数,增加的那部分学习率会比较低。
另外每一代都会保存一个检查点文件(checkpoint),因此增加代数会导致占用空间较大。
- 数据只有1张的时候,数据倍增可以开到50倍
- 数据达到100张的时候,数据倍增可以开到2~5倍
- 根据评估指标上升的情况,合理降低数据倍增
训练参数
训练代数默认12,不建议修改。
批量大小
分类默认批量大小32,检测类模型批量大小默认2。
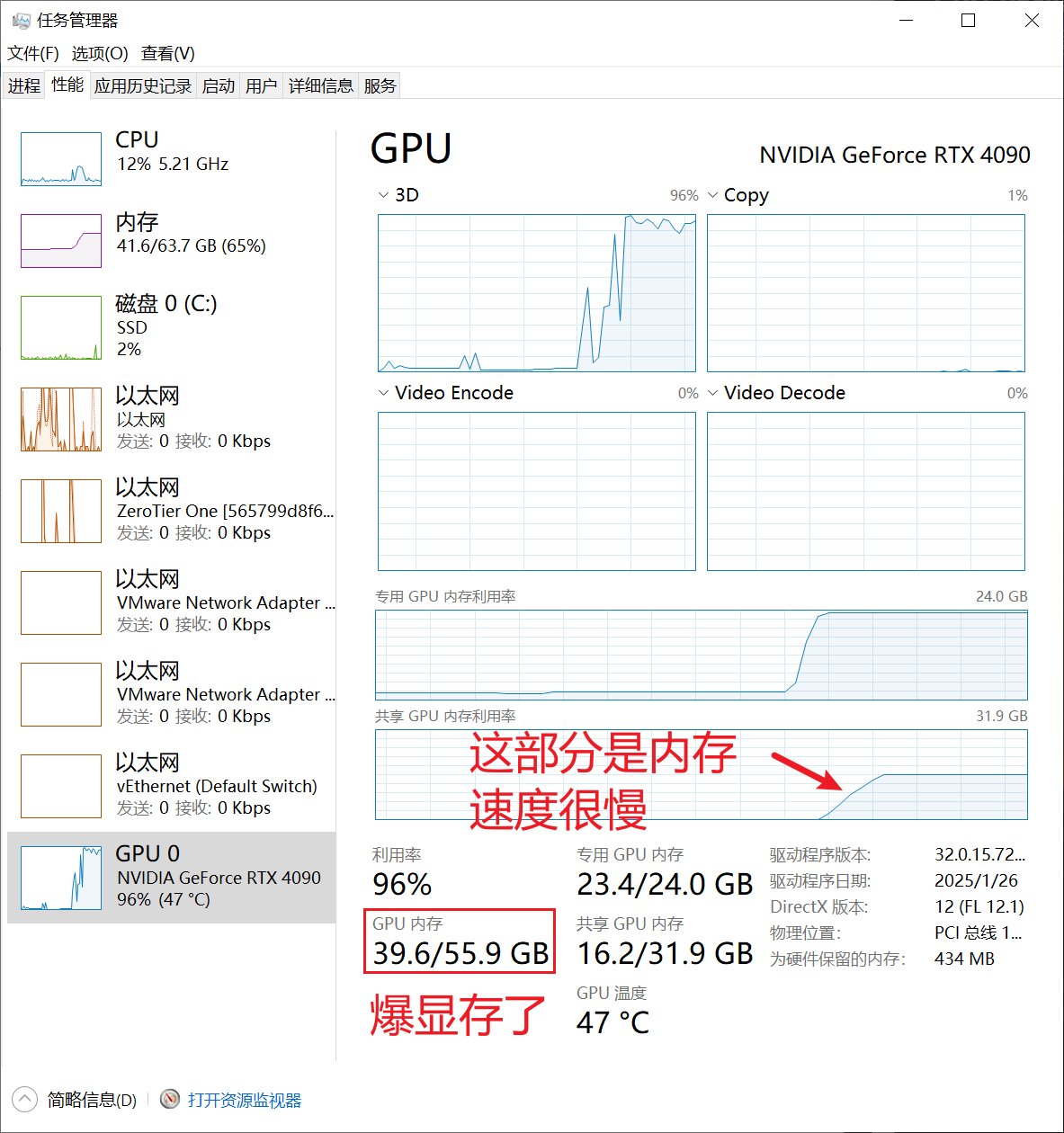
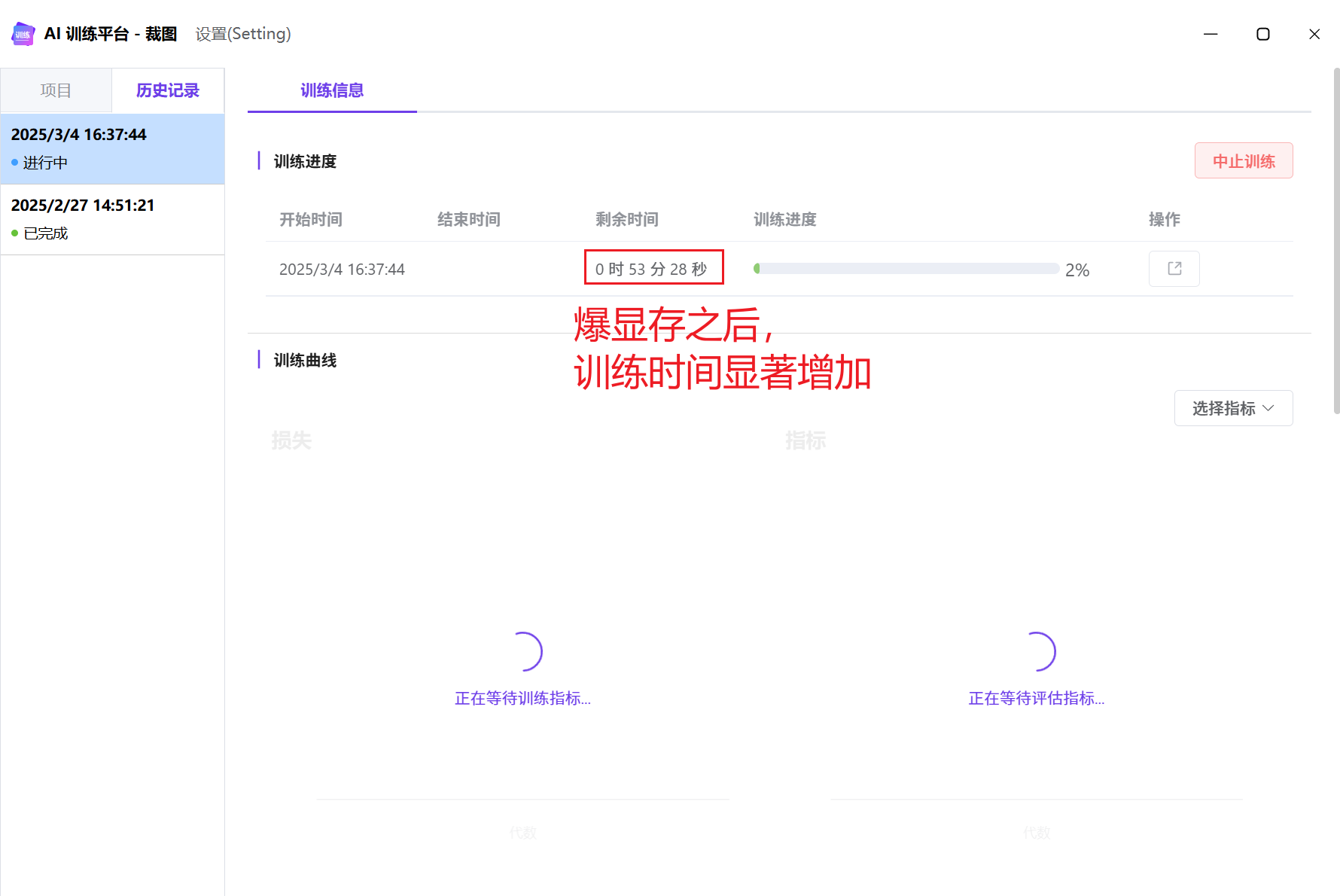
当图像尺寸比较大时(比如2048),可以适当降低批量大小,避免爆显存导致训练时间过长。
爆显存示意图:
学习率
一般使用默认值 0.001 就可以了,如果遇见训练 loss 不稳定,甚至是 loss nan 的情况,可以将学习率降低10倍,看看是否还会nan。
训练 loss 不稳定
下图可以看到 loss 出现了“插针”的现象,突然变很高,又回归正常。
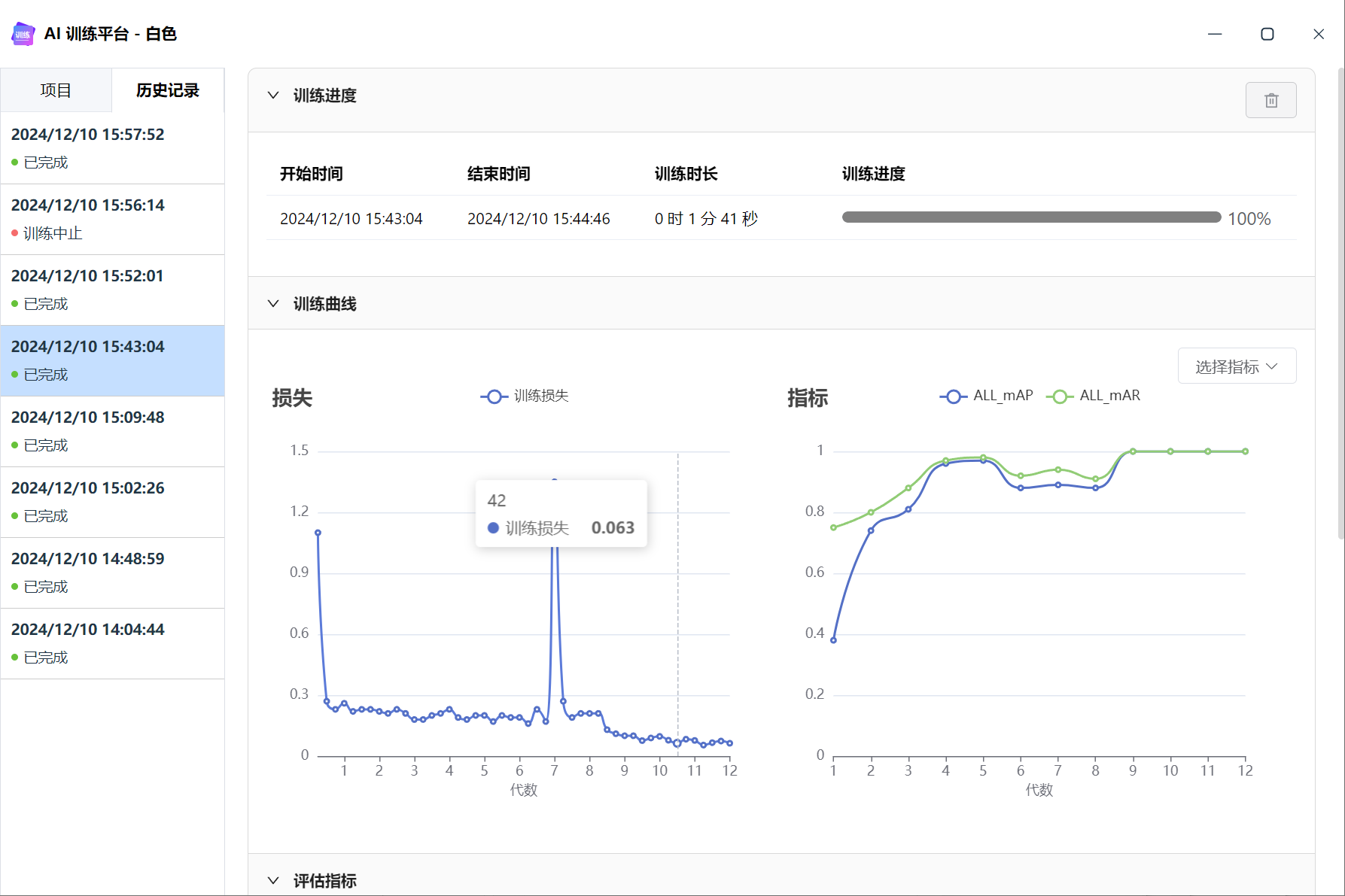
训练 loss nan
下图可以看到,训练 loss 走到第4代之后,就nan了,之后模型无法回归正常。
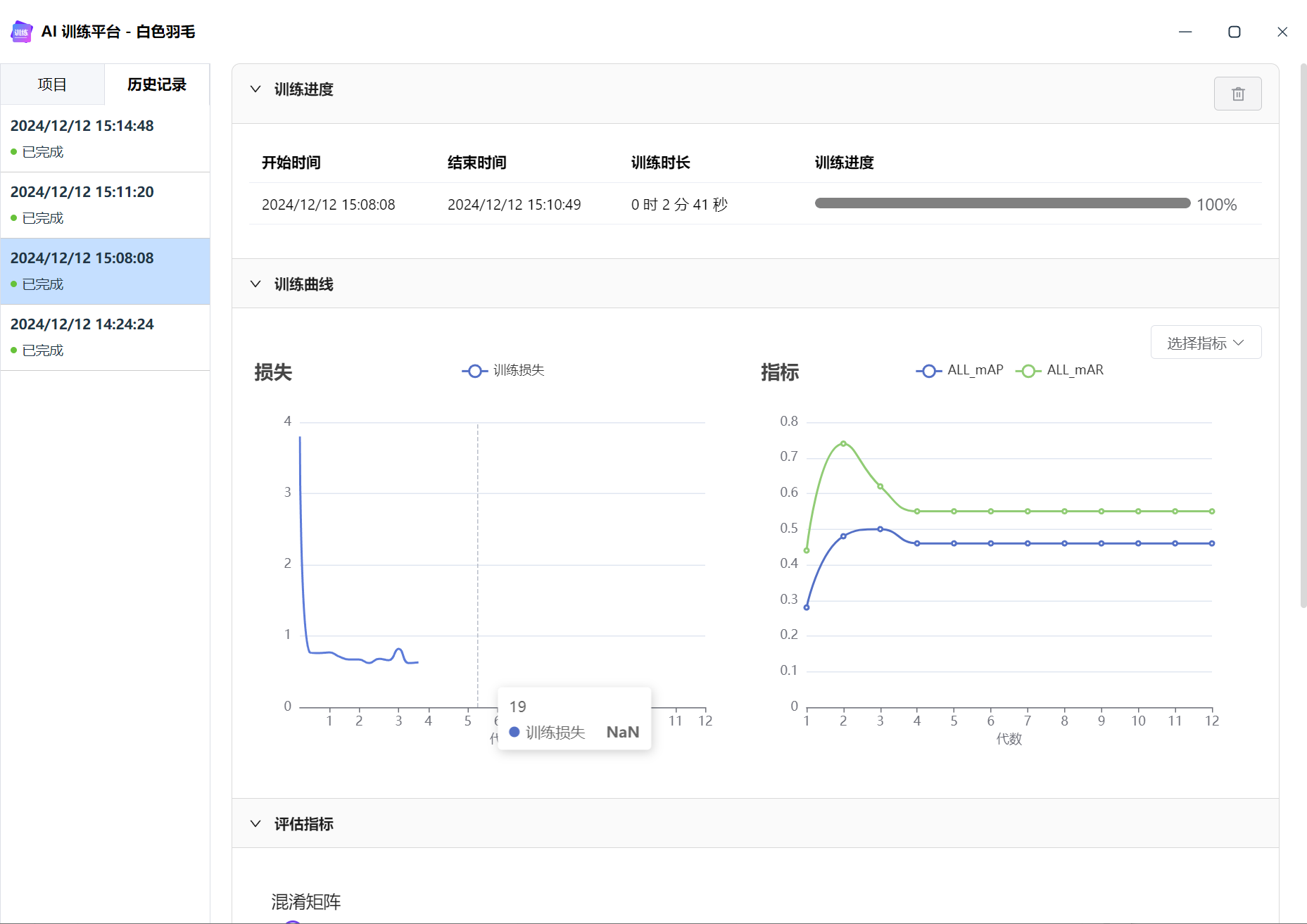
使用OK图训练
当我们做缺陷检测时,经常会遇见过检的情况,也就是将OK图检测为NG。这时就需要告诉模型,哪些是OK,让模型学习OK不应该检出结果。
过检现象
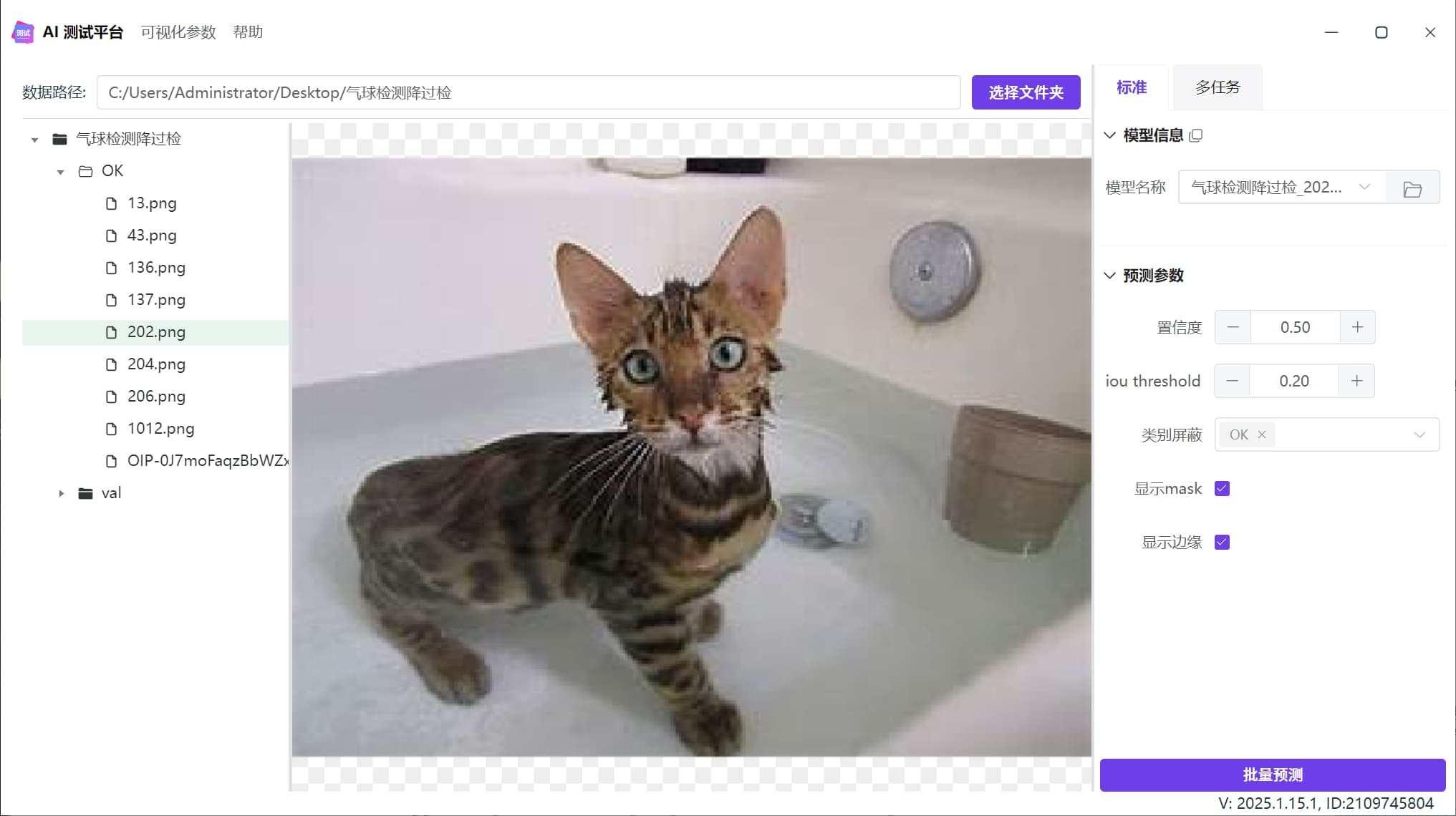
下图是一个气球检测模型,在浴缸内检测到假气球,也就是过检:
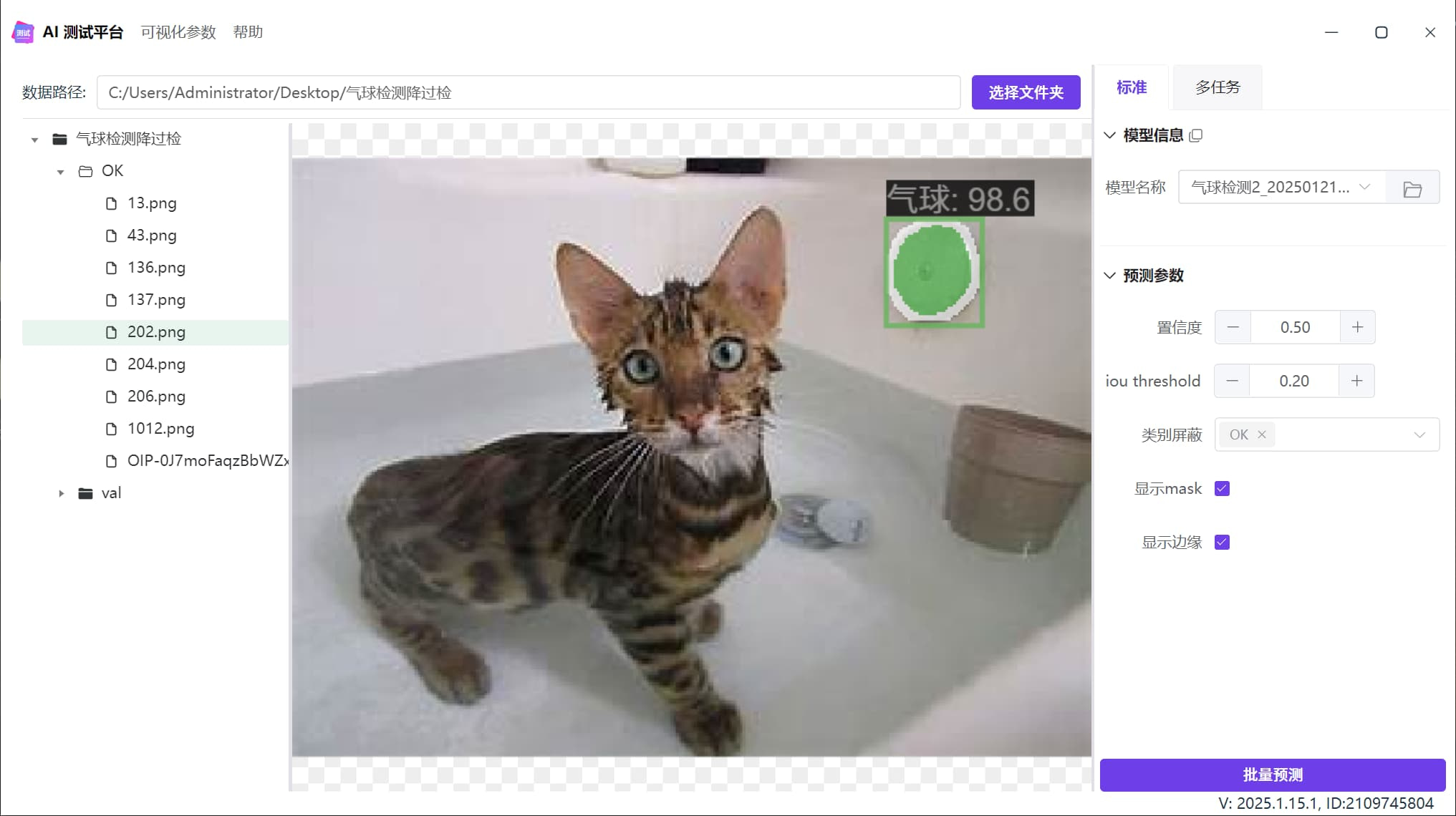
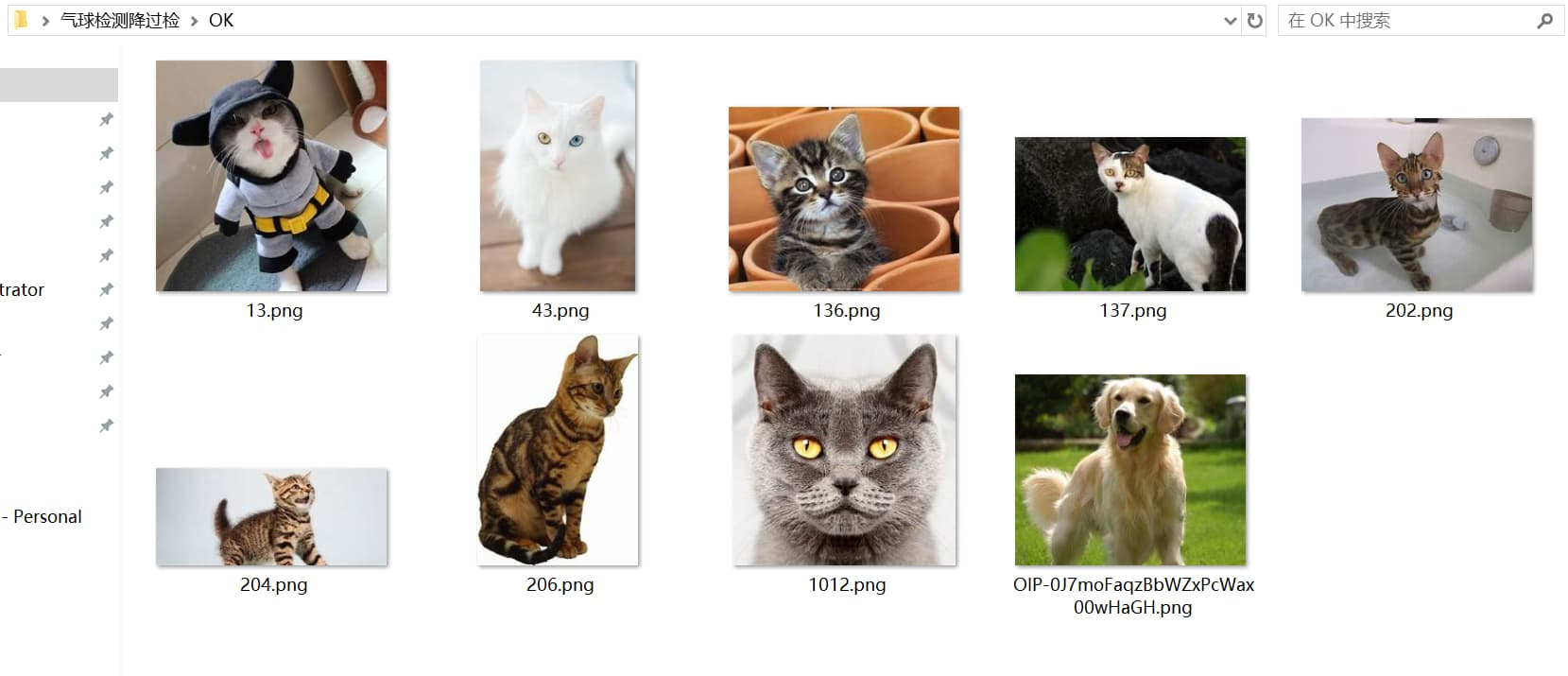
准备OK数据
当需要启动OK图训练时,我们要在数据集根目录内创建名为OK的文件夹,并且将过检图片放在这个文件夹内。
注意,不要将任何有目标物体的数据放在这个文件夹中,否则可能会造成漏检问题。
勾选使用OK图训练
在启动训练时,勾选使用OK图训练:
降过检效果
启动降过检之后,模型不会检出气泡: